We have three basic forms of information collections:
- Project collections: formed to support work on a project, contain project
related files of diverse file formats organised in elaborated organizations [1, p 139]. - Reference collections: include information items of usually one format, have
a fairly flat organizational structure and are organised by metadata or key
(time, name, topic) [1, p 139] (e.g. a collection of academic literature, a collection of music files). - Dump collections: are formed of arbitrary information items and usually
consist of information that cannot be classified in the above collections [2]. The placement is usually of a temporary nature and items from them
are sometimes deleted or renamed and moved to appropriate locations once their
role is determined.But often they just remain untouched and forgotten.
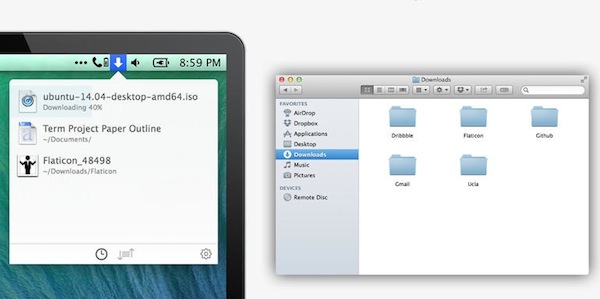
Frequent dump collections are downloads folder and desktop folder. The downloads folder can be easily organised by e.g. creation time. But the Download Organiser (£2.99) pushes things further as it can:
- automatically organise downloads by websites
- organise based on user defined filters (file type, size, source)
- open, preview files and open a containing folder
- rename files from notifications when they are downloaded
It is an interesting idea on how to organise semi-automatically acquired files drawn form the considerate research on automatically organised email based on various criteria [3].
[1] W. Jones. Keeping Found Things Found: The Study and Practice of Personal
Information Management. Morgan Kaufman, Burlington, MA, 2008.
[2] A. Kamaruddin, N. Admodisastro, and A. Dix. Before and after: User’s knowledge maturity within personal information management. International Journal
of Scientific & Engineering Research, 4, Issue 5, May 2013.
[3] M. Kljun, J. Mariani, A. Dix. Transference of PIM Research Prototype Concepts to the Mainstream: Successes or Failures Interacting with Computers, Oxford University Press. First published online: November 12, 2013

Most free apps make money by selling private information. So they are not free. To protect ourselves, we can use fake name and information.
True!
Even if apps don’t collect data and they just serve adds I wouldn’t call them free. As I wrote above these apps are “free to use” – where free means that we are not forced to use them. So not free as in free beer but free as in free speech. And as I wrote above, many apps that we pay for (to support developers or get rid of adds) sell our data as well. Sad!
One possible way around this is to use fake email and info as you suggest and as I wrote above. But as many data loggers want to share their information with their social circles this might not be an option for everyone.
One option might be a basic legislation in place to protect users in this area.
But if we prevent them from selling our data I guess that than we wouldn’t have “free” (as in free beer) apps. And we have to admit that the majority of users perceive these apps as free and don’t really think about giving up some of their privacy (which is actually just paying for the apps with your data). And maybe we wouldn’t have a plethora of apps to choose from as there would be no revenue for developers. This might be a knot hard to untangle …
If we as users do pay for apps with our data we do not really know how much our data is worth. Maybe the legislation might just require companies to publicly reveal the value of data of each individual and them we as users might get more concious and decide if the apps is worth the money.
With our data we don’t just pay for apps ONCE. We are constantly paying ALL THE TIME!